社内データをAIで活用する方法|RAGチャットボットの仕組みと導入ガイド
社内データのAI活用方法を解説。RAGの仕組みからユースケース、技術スタック、導入ステップまで、社内ナレッジをAIチャットボットで活用する実践ガイドです。

社内データのAI活用は、多くの企業が抱える「情報は蓄積されているのに活用できていない」という課題を解決する鍵です。マニュアル、議事録、社内Wiki、FAQ、過去の提案書——膨大な社内ドキュメントに答えが眠っているにもかかわらず、「どこに何が書いてあるか分からない」「検索しても欲しい情報にたどり着けない」という声は絶えません。
この課題を解決する技術として注目されているのが、RAG(Retrieval-Augmented Generation:検索拡張生成)です。本記事では、RAGの仕組みをビジネス視点で分かりやすく解説し、導入から運用までのステップを具体的に紹介します。
この記事で分かること
- RAGの仕組みと、従来のLLMだけでは解決できない課題
- 社内ナレッジ検索、カスタマーサポート、法務文書検索の3つのユースケース
- RAGシステムの構築に必要な技術スタックの全体像
- 導入ステップと失敗を避けるための注意点
- 社内データAI活用がもたらすビジネス上のROI
RAG(Retrieval-Augmented Generation)とは
従来のLLMの限界とRAGの解決策
ChatGPTやClaudeなどの大規模言語モデル(LLM)は、インターネット上の膨大なデータで学習されており、一般的な質問には高精度で回答できます。しかし、企業固有の社内情報——自社の製品仕様、社内規程、過去のプロジェクト記録など——については、当然ながら知識を持っていません。
この問題に対して、「LLMをファインチューニング(追加学習)する」というアプローチもありますが、データが更新されるたびに再学習が必要でコストがかかる、学習データに含まれない情報には対応できない、ハルシネーション(事実と異なる回答)のリスクが残る、といった課題があります。
RAGは、これらの課題をエレガントに解決するアーキテクチャです。LLMに「回答を生成させる前に、関連する社内文書を検索して参考情報として渡す」という仕組みを追加します。つまり、LLM自体に社内知識を記憶させるのではなく、質問のたびに関連情報を検索して提供するアプローチです。
RAGの仕組み
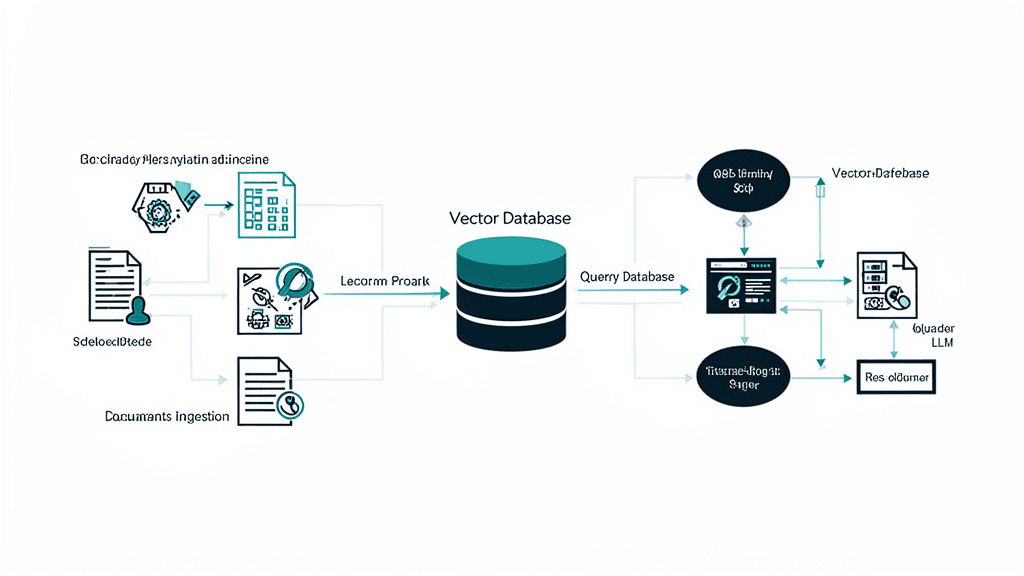
RAGの処理フローは、大きく3つのステップで構成されます。
ステップ1は、インデックス作成(事前準備)です。社内ドキュメント(PDF、Word、社内Wiki、FAQ等)をテキストに変換し、適切なサイズのチャンク(段落・セクション単位)に分割します。各チャンクをEmbeddingモデルでベクトル(数値の配列)に変換し、ベクトルデータベースに格納します。
ステップ2は、検索(Retrieval)です。ユーザーの質問を同じEmbeddingモデルでベクトルに変換し、ベクトルデータベースから意味的に類似度の高いチャンクを検索します。従来のキーワード検索と異なり、「意味的な類似性」で検索するため、質問と同じ単語が含まれていなくても関連情報を見つけられます。
ステップ3は、生成(Generation)です。検索で見つかった関連チャンクをLLMのプロンプトに「参考情報」として付与し、その情報に基づいて回答を生成します。LLMは自身の学習知識ではなく、提供された社内文書の情報をもとに回答するため、ハルシネーションのリスクが大幅に低減されます。
さらに、回答の根拠となった文書の出典を表示できるため、ユーザーは回答の正確性を自分で確認できます。これは、企業での利用において信頼性を担保する上で非常に重要な特徴です。
RAGの主なユースケース
社内ナレッジ検索チャットボット
最も導入効果が高いユースケースの一つです。社内のマニュアル、規程、Wiki、過去の議事録などをRAGのデータソースとして登録し、自然言語で質問できるチャットボットを構築します。
ビジネス上のメリットは明確です。新入社員のオンボーディング時間の短縮(社内ルールや業務手順を自分で調べられる)、ナレッジの属人化の解消(ベテラン社員に聞かなくても情報にアクセスできる)、情報検索にかかる時間の削減(McKinseyの調査では、ナレッジワーカーは業務時間の19%を情報検索に費やしている)などが挙げられます。
例えば、従業員500名の企業で1人あたり週2時間の情報検索時間を30分に短縮できた場合、年間で約39,000時間(約4,875人日)の削減効果になります。
カスタマーサポートの自動応答
自社の製品マニュアル、トラブルシューティングガイド、過去の問い合わせ履歴をデータソースとして、顧客からの問い合わせに自動応答するシステムです。
従来のルールベースのチャットボットと異なり、RAGベースのシステムは自然言語で柔軟に対応できます。顧客が「アプリにログインできない」と質問すれば、製品マニュアルから該当するトラブルシューティング手順を検索し、分かりやすい言葉で回答を生成します。
ビジネス効果としては、一次応答の自動化率向上(定型的な問い合わせの60〜80%を自動応答可能)、応答時間の短縮(24時間即時対応)、サポート担当者の負荷軽減(複雑な問い合わせに集中できる)が期待できます。
法務・コンプライアンス文書の検索
契約書、社内規程、法令、コンプライアンスガイドラインなどの法務関連文書をデータソースとし、法的な質問に対して関連する条文や規定を検索して回答するシステムです。
「この契約書のNDA条項はどうなっていますか」「個人情報の取り扱いに関する社内規程を教えてください」といった質問に対し、該当する文書の関連箇所を引用しながら回答を生成します。
ただし、法務判断は最終的に専門家が行う必要があります。RAGシステムの位置づけは「該当する文書を素早く見つけて整理する補助ツール」であり、法的判断の自動化ではない点を明確にしておくことが重要です。
RAGシステムの構築に必要な技術スタック
RAGシステムの構築には、以下の4層の技術スタックが必要です。
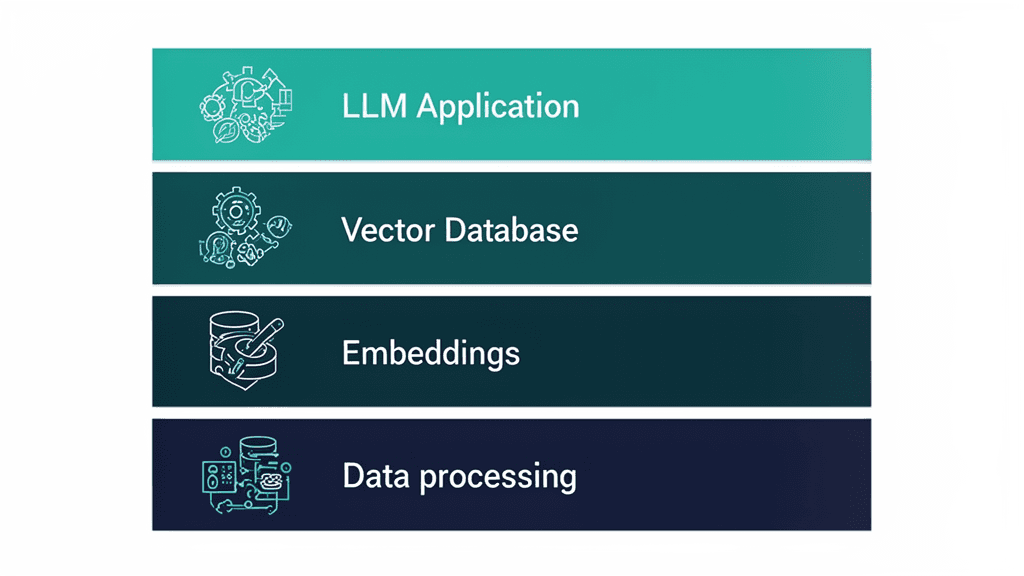
データ処理層
社内ドキュメントを取り込み、テキストに変換してチャンクに分割する層です。PDF、Word、PowerPoint、HTML、Markdownなど、様々な形式の文書に対応する必要があります。
代表的なツールとしては、LangChain(ドキュメントローダー・テキストスプリッター)、LlamaIndex(データインデックス構築フレームワーク)、Unstructured(各種ファイル形式のパーサー)などがあります。
チャンク分割の戦略は、RAGシステムの精度に大きく影響します。分割が細かすぎると文脈が失われ、粗すぎると検索精度が下がります。一般的には、500〜1,000トークン程度のチャンクサイズが推奨されますが、文書の種類に応じた調整が必要です。
Embedding層
テキストチャンクをベクトルに変換する層です。Embeddingモデルの選択が検索精度を左右します。
主要なEmbeddingモデルとしては、OpenAI text-embedding-3-large(高精度・API利用)、Cohere embed-v3(多言語対応に強い)、BGE/E5(オープンソース・セルフホスト可能)などがあります。日本語の社内文書を扱う場合、多言語対応の性能が重要なので、事前にベンチマークテストを行うことをお勧めします。
ベクトルデータベース層
生成されたベクトルを格納し、類似検索を高速に実行するデータベースです。
クラウドサービスとしてはPinecone(マネージドで運用が容易)、Qdrant(オープンソース・高性能)が人気です。既存のインフラに組み込みやすいオプションとしては、pgvector(PostgreSQLの拡張機能)、Supabase(pgvectorを内蔵したBaaS)などがあります。
セキュリティ要件が厳格な企業では、Qdrantやpgvectorを自社インフラ上にデプロイし、データが外部に出ない構成を取ることが推奨されます。
LLM・アプリケーション層
検索結果をもとに回答を生成するLLMと、ユーザーインターフェースを含むアプリケーション層です。
LLMは、OpenAI GPT-4o/GPT-4.5、Anthropic Claude 4.5 Sonnet、Google Gemini 2.5 Proなどから選択します。コスト、応答速度、回答品質のバランスで選定しますが、日本語の自然さではGPT-4oやClaude 4.5 Sonnetが安定しています。
アプリケーションのフレームワークとしては、LangChain + FastAPIの組み合わせ、LlamaIndex + Streamlitの組み合わせ、Vercel AI SDKなどが一般的です。
導入のステップと注意点
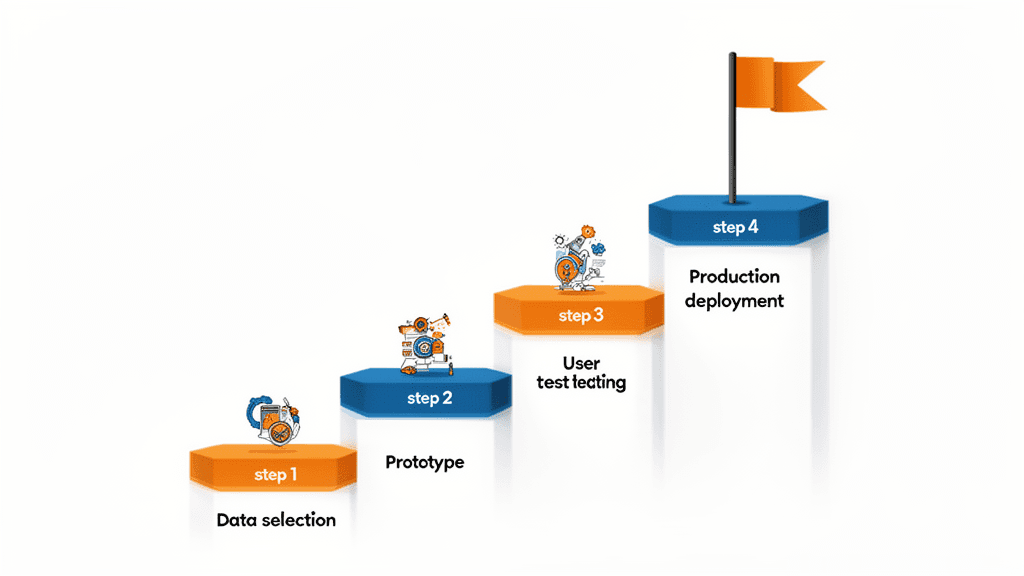
ステップ1:対象データの選定とスコープ定義
最初からすべての社内データを対象にするのではなく、効果が見込めるデータソースに絞ってスモールスタートします。
おすすめの初期対象データは、社内FAQ(整理されており即効性が高い)、製品マニュアル(カスタマーサポートの自動化に直結)、社内規程・就業規則(問い合わせが多い定型質問に対応)です。
データの品質も確認します。古すぎる情報、相互に矛盾する情報、重複している情報は、RAGの回答精度を下げる原因になるため、事前に整理・クリーニングが必要です。
ステップ2:プロトタイプの構築とテスト
選定したデータをもとにRAGシステムのプロトタイプを構築し、想定されるQ&Aパターンでテストを行います。期間は2〜4週間が目安です。
テストでは、回答の正確性(正しい情報源に基づいているか)、回答の網羅性(質問に対して十分な情報が含まれているか)、回答できないケースの挙動(対象外の質問に対して適切に「分かりません」と回答するか)、応答速度(実用的な速度で回答を返せるか)を評価します。
ステップ3:ユーザーテストとフィードバック収集
プロトタイプを少人数のテストユーザー(10〜20名程度)に公開し、実際の業務で使ってもらいます。フィードバックを収集し、検索精度の改善(チャンク分割の調整、Embeddingモデルの変更等)、UIの改善(質問の入力方法、回答の表示形式等)、データの追加・更新(テストで不足が判明したデータソースの追加)を行います。
ステップ4:本番展開と継続的改善
テスト結果を踏まえて本番環境にデプロイし、全社または対象部門に展開します。
本番運用で特に注意すべきは、データの鮮度維持です。社内文書は日々更新されるため、データの自動取り込みパイプラインを構築し、最新情報がRAGシステムに反映される仕組みを整えます。月次、あるいは文書更新のタイミングでインデックスを再構築するスケジュールを設計しましょう。
また、ユーザーからの「この回答は間違っている」「この情報が見つからない」というフィードバックを収集する仕組みを設け、継続的に精度を改善していくことが重要です。AIガバナンスのフレームワークに基づいた品質管理プロセスの整備も検討してください。
koromo の実践から — RAGシステム構築で学んだ精度改善のポイント
koromo はプロダクト開発サービスの一環として、複数のクライアント企業にRAGベースの社内チャットボットを構築してきました。ここでは、比較検証型のレポートとして、精度改善で特に効果が大きかった施策を共有します。
ある従業員400名規模のIT企業のクライアントで、社内ナレッジ検索チャットボットを構築した際の経験です。初期プロトタイプの回答正確率は約62%で、実用に耐えるレベルではありませんでした。
koromo では、以下の3つの改善施策を段階的に実施し、それぞれの効果を比較検証しました。
施策1は、チャンク分割戦略の最適化です。当初は一律500トークンでチャンク分割していましたが、文書の種類によって最適なサイズが異なることが分かりました。FAQは質問と回答のペアで1チャンク(平均200トークン)、マニュアルはセクション単位(平均800トークン)、議事録はアジェンダ項目単位(平均600トークン)に変更しました。この変更だけで、回答正確率が62%から74%に向上しました。
施策2は、ハイブリッド検索の導入です。ベクトル検索(意味的な類似性)だけでなく、BM25(キーワードマッチング)を組み合わせたハイブリッド検索に切り替えました。製品名や型番などの固有名詞は意味的な類似性では見つけにくいため、キーワード検索が補完する形です。この改善で回答正確率は74%から83%に向上しました。
施策3は、リランキングの導入です。検索で取得した候補チャンクを、Cohereのリランキングモデルで再順位付けする処理を追加しました。検索段階で20チャンクを取得し、リランキング後に上位5チャンクだけをLLMに渡すことで、ノイズが減り、回答の精度と関連性が向上しました。この追加で回答正確率は83%から91%に達しました。
最終的に、初期の62%から91%まで回答正確率を引き上げ、社内展開後は月間約3,500件の問い合わせに対応。情報システム部門への問い合わせが40%減少し、新入社員のオンボーディング期間も2週間から1.5週間に短縮されました。
この経験から学んだ最大の教訓は、「RAGの精度は、LLMの性能よりも検索パイプラインの設計で決まる」ということです。高価なLLMを使うよりも、チャンク戦略と検索手法の最適化に投資する方が費用対効果が高いケースが多いです。
よくある質問
まとめ
社内データのAI活用は、単なる技術的なトレンドではなく、企業の生産性と競争力を左右する重要な経営テーマです。RAGを活用することで、これまで眠っていた社内ナレッジを誰もがアクセスできる資産に変えることができます。
導入のポイントを振り返ります。
- まずはFAQ・マニュアルなど整理されたデータから小さく始める
- チャンク分割戦略と検索パイプラインの設計に注力する
- セキュリティ要件に応じたインフラ構成を選択する
- ユーザーフィードバックに基づく継続的な精度改善を仕組み化する
社内データのAI活用に興味があるものの、「自社にはどのユースケースが適しているか」「どこから手をつければいいか」が分からない場合は、koromo にご相談ください。課題の整理からプロトタイプ構築、本番運用まで、AIエージェントの活用も含めた最適なソリューションをご提案します。
koromo からの提案
AIツールの導入判断は、突き詰めると「投資対効果が合うか」「リスクを管理できるか」「事業にどう効くか」の3点に帰着します。koromo では、この判断に必要な材料を整理するところからご支援しています。
以下のような状況にある方は、まず現状の整理だけでも前に進むきっかけになります。
- AIで開発や業務を効率化したいが、自社に合う方法がわからない
- 社内にエンジニアがいない / 少人数で、AI導入の進め方に見当がつかない
- 外注先の開発会社にAI活用を提案したいが、何を求めればいいか整理できていない
- 「AIを使えばコスト削減できるはず」と感じているが、具体的な試算ができていない
ツールを使った上で相談したい方はお問い合わせフォームから「AI活用の相談」とご記載ください。初回の壁打ち(30分)は無料で対応しています。


